
The emergence of AI has brought promises of leaner teams and lower payroll costs – a potential game-changer for early-stage companies. But if you’re an AI-enabled company, what’s often misunderstood is the challenging unit economics of compute and how this changes your cost structure and ability to scale. This post examines the financial implications of AI and how compute costs in particular can alter a company’s path to profitability.

What is “Compute,” and Why Does It Matter?
In the world of AI, compute refers to the processing power required to train and serve models. This involves specialized hardware such as graphic process units (GPUs) and tensor processing units (TPUs), hosted either on-premises or via the cloud.
Training compute refers to the processing power required to train and fine-tune models, experiment with new architectures, or run simulations. Inference or serving compute refers to the processing power required to serve a response to users. In other words, inference compute is used to produce an output – such as a chat response or image – or to execute a task.
Most AI companies “rent” their compute from a data infrastructure company. The large data infrastructure companies include Microsoft Azure, AWS and Google Cloud. There are also new players emerging in the space, including CoreWeave, TensorWave, Nebius, and Digital Ocean.
Compute is typically priced per hour of usage and the rates vary by company and by GPU type (A100, H100, H200, etc). For AI-native companies – think OpenAI, Perplexity, Midjourney to name a few – compute is usually the largest expense line on the P&L. For AI-enabled companies – these are companies that are incorporating AI into their ops in a big way – compute is a material expense and growing.
Considerations for the Finance Team
For CFOs and other finance professionals, there are three fundamental things to understand about AI compute.
- AI-related inference compute is a relatively inefficient form of algorithmic processing. Every user interaction requires complex, algorithmic computations. This means you spend a lot on inference compute to complete a task or generate an output. Finding ways to use AI more efficiently and surgically is absolutely critical. See the table below for more about why AI compute is so expensive today.
- Inference compute is as close as it gets to a purely variable cost. As mentioned above, you typically rent serving compute by the hour. The more compute you use, the more you spend. This is a very different cost structure from the next best substitute to compute, which is headcount. Most software developers and engineers are salaried and while you can hire and fire as needed, the reality is, headcount costs tend to move up or down in a step function. Headcount is a partially variable cost.
- Many AI companies not only spend on inference, they also spend on training. Training compute can get really expensive. The larger the dataset you train on, the more expensive the compute. In addition training tends to be iterative as companies constantly adjust and optimize their internal parameters through repeated calculations, so its a partially variable cost. Regardless of how intense the training is, its an added cost on top of the inference compute that often gets overlooked.
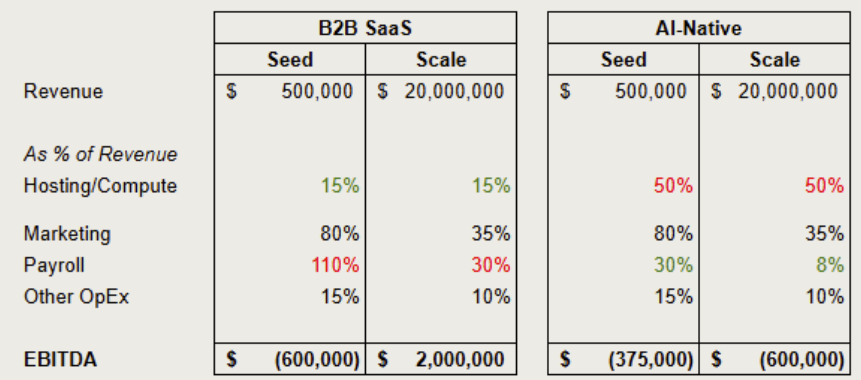
In the table below, I illustrate how an AI-native company compares to a traditional B2B SaaS company as they scale. For the B2B SaaS company, the table presents the traditional cost structure, where the marginal cost of serving an incremental customer is extremely low (but not zero). A traditional B2B SaaS company has to grow headcount to maintain its software, release new features, and provide customer support. Most of these costs are partially variable, not purely variable. As a B2B SaaS company grows its customer base, it can serve its customers with increasing efficiency. The software development cost to release a new feature is essentially the same whether the company has 10 or 10,000 customers.
Contrast this with an AI company. An AI company’s compute costs are a much larger part of the cost structure. These compute costs are highly inefficient and purely variable. As an AI company grows its customer base, a high proportion of its cost structure also increases in lockstep. The path to profitability is a lot less clear. It takes sophisticated, reliable forecasting and ruthless monitoring of costs for AI companies to scale profitably.
________________________________________________________________________________________________________
Table: Why AI Compute is So Expensive
| Scarce, expensive hardware | GPUs like NVIDIA’s H100 can cost tens of thousands of dollars, with demand far outpacing supply. |
| Inefficient inference | Unlike SaaS, every user interaction requires complex, algorithmic computations. This is taxing on the infrastructure. In addition, AI workloads are energy-intensive. |
| Fine-tuning is difficult in practice | In theory, fine-tuning can make AI models more efficient by customizing them for specific tasks, however, in practice, many tasks are too broad or complex for narrow fine-tuned models to handle accurately. As a result, many companies fall back on serving full foundation models to ensure reliability and reduce hallucinations. This tends to keep inference compute costs high |
| Training at scale | State-of-the-art models with huge volumes of parameters require millions of dollars in compute just to train once. They then require ongoing investment in continuous training to remain competitive. |
Where We Can Help
At Karlon Group, we specialize in fractional CFO services for AI, SaaS, and tech startups, and we’ve seen firsthand how unchecked compute spend can derail even the most promising products. Here’s how we help:
Modeling Realistic Compute Scenarios:
We work with technical teams to build dynamic models that estimate training and inference costs based on user projections, model size, and cloud pricing. Our methodology’s underlying assumptions and formulas help prevent budget surprises and sets a foundation for sustainable scaling.
Unit Economics & Gross Margin Analysis:
Many founders assume cloud credits will carry them … until they don’t. We help teams understand the true cost per user and optimize for margins.
Vendor Negotiation & Cloud Cost Strategy:
We help founders negotiate cloud deals, evaluate compute lease options, and explore hybrid strategies – including repatriation or local inference – that can slash recurring costs.
Investor-Ready Financials:
AI investors are asking tougher questions. We prepare finance decks, data rooms, and financial plans that show how your business can achieve AI-native unit economics.
Burn Rate Management & Forecasting:
Compute costs don’t scale linearly. We help forecast infrastructure costs as product usage grows, identify inflection points, and recommend when to raise capital (and how much).
About the Author:
Sean Scanlon is co-founder and Managing Partner at Karlon Group, a fractional finance and accounting firm that helps companies build, scale, and optimize their finance and accounting functions. Karlon Group works with companies across SaaS, consumer, manufacturing, and technology, offering a full suite of finance and accounting support tailored to each client’s needs.